What would you do if you were given a year to work on/research whatever you wanted to work on? I think like many people would, I had an immediate answer. If there’s one topic that really lights my fire, it’s open law and other types of open information. So of course, I said “I’m going to work on open law and information” when I was granted this opportunity. But what does that mean? It seems like my answer to that question changes every time I ask it of myself.
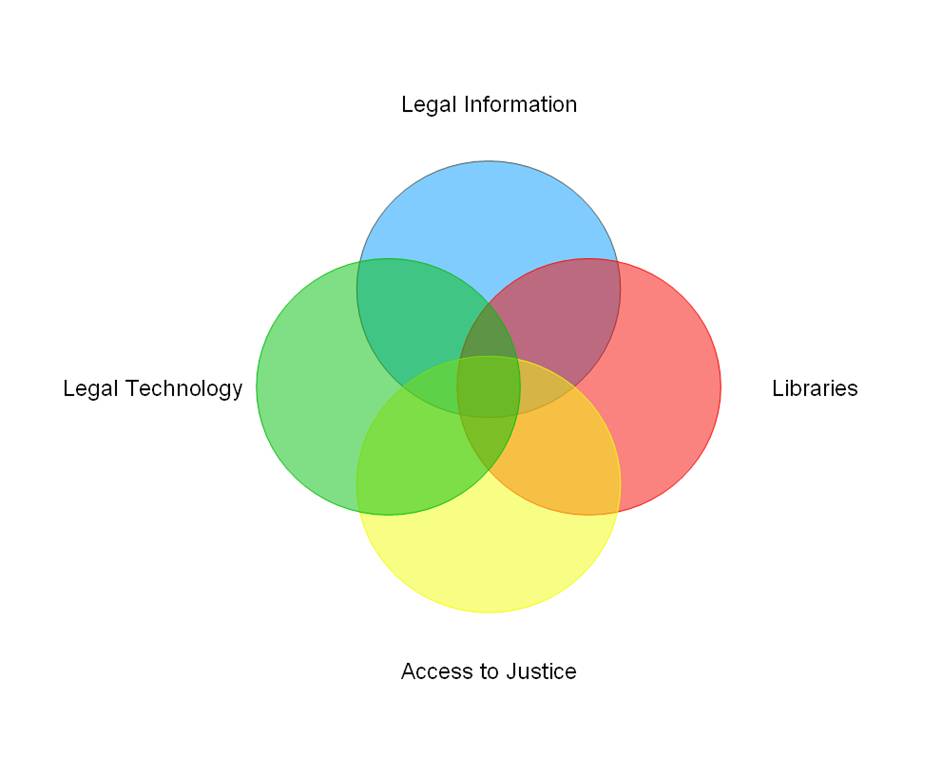
Imagine, if you will, a Venn diagram made of four circles. One is labeled “legal information”, one is labeled “access to justice”, one is labeled “legal technology” and one is labeled “libraries.” So something like this:
My ultimate goal is to work in areas that are smack dab in the center of that Venn diagram, or at least three of the four circles. Of course, related to all of the above are intersections with legal education and legal practice. While those won’t be my primary foci (at least not at current plan), there will be times when I touch on those topics. But, like, I don’t care about the business of law and I’m currently pretty burnt out on the idea of “improving” legal education when the actors in that process – not commentators like me – are the ones with the power to actually make changes, so keep that in mind with anything I do in those areas.
PROJECTS AND PLANS
Here’s a rough idea of things I’d like to work on this year. Some of the plans are more concrete than others.
1) My first goal is to get my arms around the current state of legal information on the web, as published (or outsourced by) the creating government bodies. So this means a rather dreary period of data collection, similar to the survey that AALL performed almost five years ago. Right now I’m still in the process of trying to decide exactly what data to collect and it what container I should collect it in, especially as ultimately I’d like to create a tool where a person could enter some geographic data (e.g. address, zip code, county, etc.) and receive in return links or information to let them know what jurisdictions they are in and what source(s) of law they should consult.
2) Related to above data collection project, I have a hypothesis that similar to the concept of “food deserts”, there are “justice deserts” (a term I’m trying to find an alternative to, as it sounds too much like “just desserts”) or “legal access deserts” where a person, either through geography or availability of content or copyright is unable to adequately assist themselves in legal issues. (Important since studies have shown that 80% of the people that need legal assistance are unable or unwilling to consult an attorney.) So that’s also informing my decisions on what data to collect.
3) I am also curious about what types of resources are available to the public via law libraries. There has been a recent survey published by the AALL Special Committee on Access to Justice (survey) (report) that covered the general idea, but I’d like to create a survey that goes a little deeper into the content of the services offered. I’m curious because it’s been my experience that some online services offered specifically for pro-se patrons only cover the local jurisdiction primary law and very little in the way of secondary sources.
4) Related to the legal access desert idea, I’ve already found that it’s almost impossible to find case law (unless you’re talking about US Supreme Court cases) before 1950. Is that a big problem or not? So, one project idea I have is to do a citation analysis and see what cases are being cited. The big question is “what corpus do I check”? So that project will take some planning and thought.
5) I’m a strong believer that libraries need to take more of a leadership role when it comes to publishing and preserving legal information. (And publishing other types of information…). Is it possible for there to be some sort of “legal information archiving tool” that can be easily deployed and used by libraries?
6) A technical project (as opposed to research) that I’ve been thinking about it topic modeling. Specifically, creating an open index of US case law. I think one is needed because full text searching of case law – as available to most people using open law sites – is insufficient for legal research. There needs to be a back bone there in order to assist with searching. I don’t know how hard this will be. This project is still waaaaay early in the planning stages. I saw a brief demonstration performed by the people at the Legal Information Institute, so I need to get with them and work on this, me thinks.
7) I’m also hyped up on block chain technology and it’s possibilities for authenticating legal information. So throw that into the “thinking about” pile.
There’s some other things, but that’s a good start for now. I have some even vaguer ideas, so vague as to not be worth writing down. While I am terrified of getting to June and having nothing to show for my year off, I also don’t want to lock myself into plans so that I cannot pivot and try new things that catch my attention.
BEING SELFISH
I really feel a big obligation to do something useful during the time of my fellowship, since I am so lucky to be given this opportunity. But I’m also here at Harvard to learn and improve myself and my skillset. It’s been ten years since I finished grad school and the world, technology speaking, has undergone a huge revolution. In addition to the Berkman community activities, I also want to take the time to learn some new tech skills and gain other types of skills and knowledge. Part of it is going to be very necessary, as I want to build some tools that come out of my research and I don’t want to rely on outside developers. So, EdX, CodeAcademy, etc here I come. I also hope to attend some relevant conferences through the year, including LVI in Sydney, in order to expand my horizons and professionally related social circle.